如何使用10行代码识别图片中的物体
日期:2020年3月17日
标签:图片识别,人工智能
总结
第一步:打开无相编译器。
第二步:输入以下代码:
使用即时模式。
使用物体识别。
使用执行。
物体识别执行为小狗添加触发行为:
使用输出。
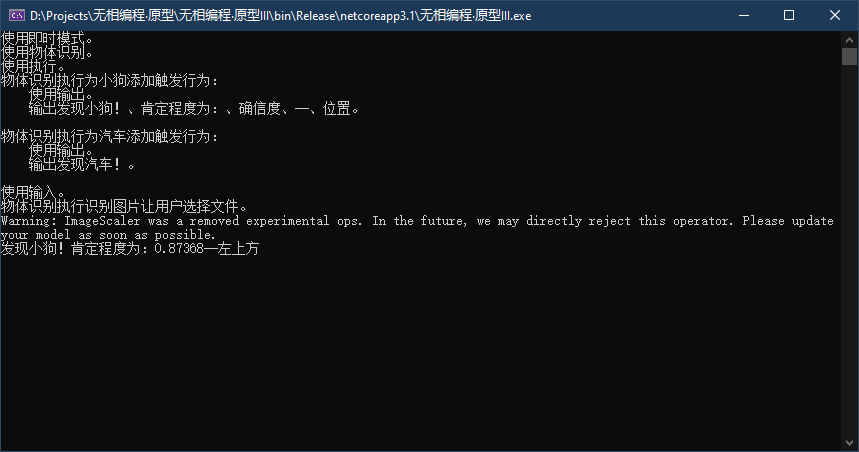
输出发现小狗!、肯定程度为:、确信度、——、位置。
使用输入。
物体识别执行识别图片让用户选择文件。
第三步:完成!
操作截图
第一步:打开编译器。
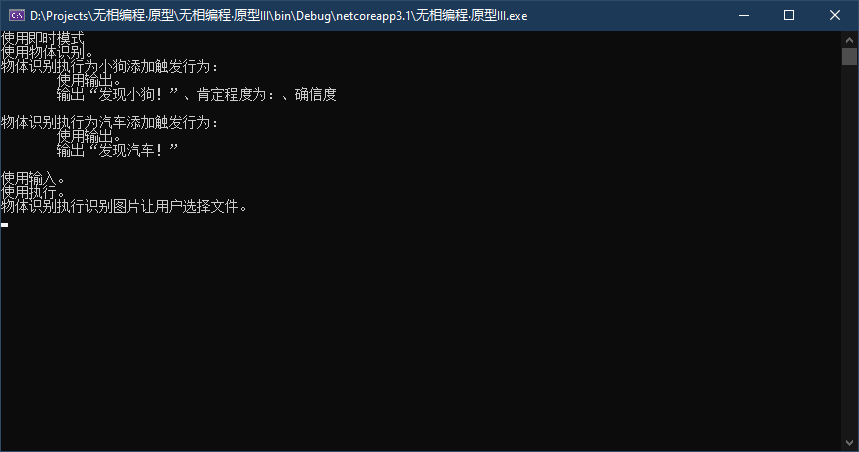
第二步:输入代码并执行。
选择图片文件。
第三步:查看结果。
视频演示
备注
请忽略上面截图中的英文。😉
目前图片识别技术还不很成熟,此演示使用了无相编程默认的预先训练模型TinyYolo2,精度上还有所欠缺。 同样是识别“小狗”,虽然可以识别黑衣人亮度很低的画面中的巴哥犬,但是却无法识别对比清晰的电影万万没想到海报中的地狱恶犬(品种未知)。 对于需要更为准确的应用,还得使用更底层的参数进行微调。




额外参考
使用相似的技巧,我们可以写出如下代码来实现更实用的功能!
使用注释。
注释:
以下代码演示了使用图片识别和图片识别事件来自动将当前文件夹中所有包含“小狗”的图片移动到名为“小狗”的子文件夹中。
使用并列句式。
使用物体识别。
使用文件、文件夹、路径。
使用遍历、助词“的”、真否、定义。
定义当前路径为文件夹的当前路径。
设置物体识别的标记结果为真。
物体识别执行为小狗添加触发行为:
定义旧文件名为文件执行小狗获取文件名。
定义新路径为路径执行组合:当前路径,“小狗”,旧文件名。
文件执行拷贝图片路径至新路径。
遍历文件夹执行当前路径选择所有文件:
物体识别执行识别图片文件。
使用计算机视觉。
计算机视觉执行从图片生成视频:
源路径为当前路径,
输出路径为路径执行组合:当前路径,视频.mp4